redis学习
部署方式
主从复制
Redis的主从复制是一种数据复制机制,它将一台Redis服务器的数据复制到其他的Redis服务器。其中,前者称为主节点(master),后者称为从节点(slave)。数据的复制是单向的,只能由主节点到从节点。默认情况下,每台Redis服务器都是主节点,且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。主从复制的作用主要包括:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
缺点:主节点挂掉后,不可用。
哨兵模式
基于主从复制,它可以自动感知系统故障、自动故障转移,具备以下能力:
- 监控(Monitoring):持续监控Redis主节点、从节点是否处于预期的工作状态。
- 通知(Notification):哨兵可以把Redis实例的运行故障信息通过API通知监控系统或者其他应用程序。
- 自动故障恢复(Automatic failover):当主节点运行故障时,哨兵会启动自动故障恢复流程:某个从节点会升级为主节点,其他从节点会使用新的主节点进行主从复制,通知客户端使用新的主节点进行。
- 配置中心(Configuration provider):哨兵可以作为客户端服务发现的授权源,客户端连接到哨兵请求给定服务的Redis主节点地址。如果发生故障转移,哨兵会通知新的地址。
集群模式
Redis集群使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现:一个Redis集群包含16384个哈希槽(hash slot),数据库中的每个键都属于这16384个哈希槽的其中一个,集群使用公式CRC16(key) % 16384来计算键key属于哪个槽,其中CRC16(key)语句用于计算键key的CRC16校验和。集群中的每个节点负责处理一部分哈希槽。这种将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点。
至少需要3个节点(选举半数需要),一个节点包含一个主节点,多个从节点(主从复制)
常见问题
redis和数据库的数据一致性
读数据
先从redis读取数据,没有再从数据库读数据,并写入到redis中
写数据
- 双删方案
先删除redis,再写数据库,随机一小段时间,再删一次redis
- 先写数据库,再删除redis
其它方案,高并发场景可能读到旧数据,或者写入旧数据库到缓存
一致性
因为不是原子性操作,高并发场景可能有删除失败的情况,数据同步推荐3种方式
- 业务代码定时任务删除失败的数据
- mq
- binlog
缓存雪崩
定义:大量key同时失效,请求打向数据库。
原因及解决措施:
- key的过期时间设置的一样了,解决措施:每次设置过期时间,加上一个小点的随机数
- redis服务挂了,解决措施:高可用方案,集群。
缓存击穿
定义:热点key失效,请求打向数据库。
解决措施:热点key不设置过期时间
缓存穿透
定义:key在redis和数据库中都不存在
原因:误删或恶意攻击
解决措施:
- 前端参数校验
- 把不存在的key缓存起来,并返回空对象,设置一个短的过期时间
- 布隆过滤器(准确快速的判断某个数据是否在大数据量集合中,并且不占用内存),常用实现
- redisson
- lettuce
- guava
Redis是单线程的吗
Redis 单线程指的是「接收客户端请求->解析请求 ->进行数据读写等操作->发生数据给客户端」这个过程是由一个线程(主线程)来完成的,这也是我们常说 Redis 是单线程的原因。
但是,Redis 程序并不是单线程的,Redis 在启动的时候,是会启动后台线程的:比如持久化、 异步删除、集群数据同步等,是由额外的线程来执行的。
单线程为什么还这么快?
- Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,因此 Redis 瓶颈可能是机器的内存或者网络带宽,而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了;
- Redis 采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题。
- Redis 采用了I/O 多路复用机制处理大量的客户端 Socket 请求,IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听 Socket 和已连接 Socket。内核会一直监听这些 Socket 上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
Redis 6.0 之前为什么使用单线程?
官方回答:CPU 并不是制约 Redis 性能表现的瓶颈所在,更多情况下是受到内存大小和网络I/O的限制,所以 Redis 核心网络模型使用单线程并没有什么问题,如果你想要使用服务的多核CPU,可以在一台服务器上启动多个节点或者采用分片集群的方式。
除了上面的官方回答,选择单线程的原因也有下面的考虑。
使用了单线程后,可维护性高,多线程模型虽然在某些方面表现优异,但是它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,增加了系统复杂度、同时可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗。
Redis 6.0 之后为什么引入了多线程?
虽然 Redis 的主要工作(网络 I/O 和执行命令)一直是单线程模型,但是在 Redis 6.0 版本之后,也采用了多个 I/O 线程来处理网络请求,这是因为随着网络硬件的性能提升,Redis 的性能瓶颈有时会出现在网络 I/O 的处理上。
所以为了提高网络请求处理的并行度,Redis 6.0 对于网络请求采用多线程来处理。但是对于读写命令,Redis 仍然使用单线程来处理,所以大家不要误解 Redis 有多线程同时执行命令。
Redis 官方表示,Redis 6.0 版本引入的多线程 I/O 特性对性能提升至少是一倍以上。
Redis 6.0 版本支持的 I/O 多线程特性,默认是 I/O 多线程只处理写操作(write client socket),并不会以多线程的方式处理读操作(read client socket)。要想开启多线程处理客户端读请求,就需要把 Redis.conf 配置文件中的 io-threads-do-reads 配置项设为 yes。
1 | //读请求也使用io多线程 |
同时, Redis.conf 配置文件中提供了 IO 多线程个数的配置项。
1 | // io-threads N,表示启用 N-1 个 I/O 多线程(主线程也算一个 I/O 线程) |
关于线程数的设置,官方的建议是如果为 4 核的 CPU,建议线程数设置为 2 或 3,如果为 8 核 CPU 建议线程数设置为 6,线程数一定要小于机器核数,线程数并不是越大越好。因此, Redis 6.0 版本之后,Redis 在启动的时候,默认情况下会有 6 个线程:
- Redis-server :Redis的主线程,主要负责执行命令;
- bio_close_file、bio_aof_fsync、bio_lazy_free:三个后台线程,分别异步处理关闭文件任务、AOF刷盘任务、释放内存任务;
- io_thd_1、io_thd_2、io_thd_3:三个 I/O 线程,io-threads 默认是 4 ,所以会启动 3(4-1)个 I/O 多线程,用来分担 Redis 网络 I/O 的压力。
其它
- 避免big-key,hash更均匀
- 避免keys*,scan操作,影响性能
持久化
RDB(redis database)
生成指定时间间隔内的Redis内存中数据快照,是一个二进制文件dump.rdb。RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。RDB在恢复大数据集时的速度比AOF的恢复速度要快。RDB快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。RDB机制是通过把某个时刻的所有数据生成一个快照来保存,提供了三种触发机制:save、bgsave、自动化。推荐使用,凌晨定时任务执行,每次关闭启动的时候执行下bgsave,这样对性能比较好。
AOF(append only file)
记录Redis除了查询以外的所有写命令,并在Redis服务启动时,通过重新执行这些命令来还原数据。AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。根据所使用的fsync策略,AOF的速度可能会比RDB慢。通常fsync设置为每秒一次就能获得比较高的性能,而关闭fsync可以让AOF的速度和RDB一样快。AOF日志文件的大小一般会比RDB文件大。AOF机制也有三种触发机制:每修改同步always、每秒同步everysec、不同步no。
Java客户端
Jedis是一个比较纯粹的Redis客户端,几乎没有提供什么高级功能。它的性能比较差,所以如果您不需要使用Redis的高级功能,建议使用Lettuce。Jedis客户端实例不是线程安全的,所以需要通过连接池来使用Jedis。
Lettuce是一个线程安全的Redis客户端,它满足了大多数场景需求。所有Redis用户的操作是单线程执行的,使用多连接并不能改善一个应用的性能。使用阻塞操作的通常与获得专用连接的工作线程结合在一起。使用Redis事务是使用动态连接池的典型场景,因为需要专用连接的线程数趋于动态,也就是说动态连接池的需求是有限的。
Redisson提供了很多开箱即用的Redis高级功能,如果您的应用中需要使用到Redis的高级功能,建议使用Redisson。Redisson支持分布式锁、分布式集合、分布式对象、分布式限流等功能,可以很方便地实现分布式应用。Redisson的缺点是它的性能比较差,所以不适合对性能要求比较高的场景。
spring boot date redis
基于lettuce,Spring RedisTemplate封装方法,调用方便。
分布式锁
事务
MULTI, EXEC, DISCARD and WATCH
SETNX(SET IF NOT EXIST)
Redis是一个单线程模型,它通过队列来实现多个客户端的请求排队执行。这意味着,在Redis中执行的每个命令都是原子性的,不会存在线程安全问题。Redis提供了多个命令可以实现原子性的操作,如SETNX、GETSET等,它们都是通过Redis的事务机制以及WATCH命令来实现的。在分布式锁的实现中,我们可以使用SETNX命令来实现锁的获取,使用DEL命令来实现锁的释放。
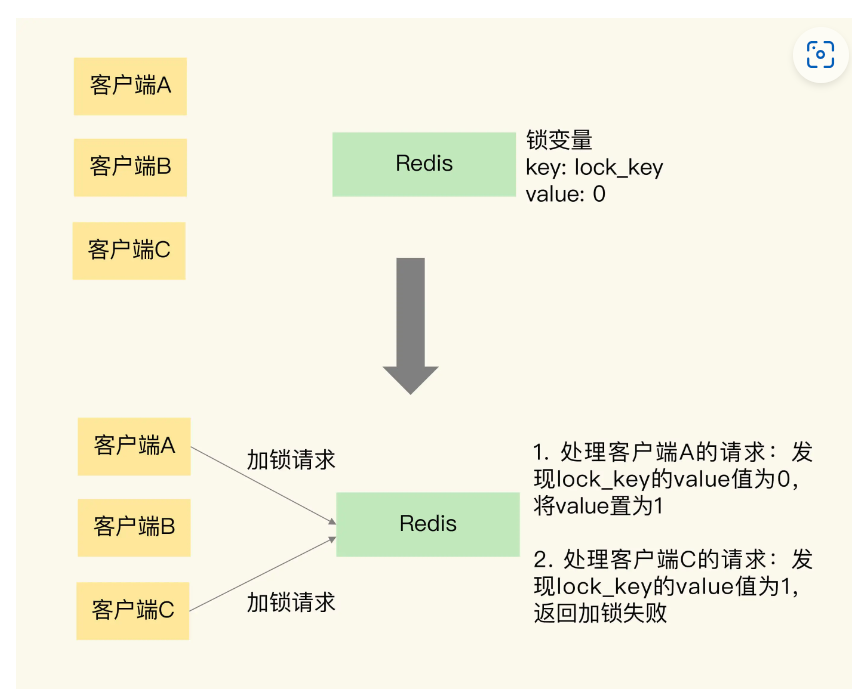
对应Spring RedisTemplate中的setIfAbsent()方法
redisson
上述方案在高并发场景会出现死锁问题,redisson的redlock搭配集群模式可实现高可用的分布式锁。
Redisson 分布式缓存dcs